creation_time — Время, когда запрос был скомпилирован. Поскольку при старте сервера кэш пустой, данное время всегда больше либо равно моменту запуска сервиса. Если время, указанное в этом столбце позже, чем предполагаемое (первое использование процедуры), это говорит о том, что запрос по тем или иным причинам был рекомпилирован.
last_execution_time — Момент фактического последнего выполнения запроса.
execution_count — сколько раз запрос был выполнен с момента компиляции Количество выполнений позволяет найти ошибки в алгоритмах — часто в наиболее выполняемых запросах оказываются те, которые находятся внутри каких-либо циклов однако могут быть выполнены перед самим циклом один раз. Например, получение каких-либо параметров из базы данных, не меняющихся внутри цикла.
CPU — Суммарное время использования процессора в миллисекундах. Если запрос обрабатывается параллельно, то это время может превысить общее время выполнения запроса, поскольку суммируется время использования запроса каждым ядром. Во время использования процессора включается только фактическая нагрузка на ядра, в нее не входят ожидания каких-либо ресурсов. Очевидно, что данный показатель позволяет выявлять запросы, наиболее сильно загружающие процессор. AvgCPUTime — Средняя загрузка процессора на один запрос.
TotDuration — Общее время выполнения запроса, в миллисекундах. Данный параметр может быть использован для поиска тех запросов, которые, независимо от причины выполняются «наиболее долго». Если общее время выполнения запроса существенно ниже времени CPU (с поправкой на параллелизм) — это говорит о том, что при выполнения запроса были ожидания каких-либо ресурсов. В большинстве случаев это связано с дисковой активностью или блокировками, но также это может быть сетевой интерфейс или другой ресурс. Полный список типов ожиданий можно посмотреть в описании представления
sys.dm_os_wait_stats. AvgDur — среднее время выполнения запроса в миллисекундах.
Reads — общее количество чтений. Это пожалуй лучший агрегатный показатель, позволяющий выявить наиболее нагружающие сервер запросы. Логическое чтение — это разовое обращение к странице данных, физические чтения не учитываются. В рамках выполнения одного запроса, могут происходить неоднократные обращения к одной и той же странице. Чем больше обращений к страницам, тем больше требуется дисковых чтений, памяти и, если речь идет о повторных обращениях, большее время требуется удерживать страницы в памяти.
Writes — общее количество изменений страниц данных. Характеризует то, как запрос «нагружает» дисковую систему операциями записи. Следует помнить, что этот показатель может быть больше 0 не только у тех запросов, которые явно меняют данные, но также и у тех, которые сохраняют промежуточные данные в tempdb.
AggIO — Общее количество логических операций ввода-вывода (суммарно) Как правило, количество логических чтений на порядки превышает количество операций записи, поэтому этот показатель сам по себе для анализа применим в редких случаях.
AvgIO — Среднее количество логических дисковых операций на одно выполнение запроса. Значение данного показателя можно анализировать из следующих соображений: Одна страница данных — это 8192 байта. Можно получить среднее количество байт данных, «обрабатываемых» данным запросом. Если этот объем превышает реальное количество данных, которые обрабатывает запрос (суммарный объем данных в используемых в запросе таблицах), это говорит о том, что был выбран заведомо плохой план выполнения и требуется заняться оптимизацией данного запроса. Я встречал случай, когда один запрос делал количество обращений, эквивалентных объему в 5Тб, при этом общий объем данных в это БД был 300Гб, а объем данных в таблицах, задействованных в запросе не превышал 10Гб. В общем можно описать одну причину такого поведения сервера — вместо использования индекса сервер предпочитает сканировать таблицу или наоборот. Если объем логических чтений в разы превосходит общие объем данных, то это вызвано повторным обращениям к одним и тем же страницам данных. Помимо того, что в одном запросе таблица может быть использована несколько раз, к одним и тем же страницам сервер обращается например в случаях, когда используется индекс и по результатам поиска по нему, найденные некоторые строки данных лежат на одной и той же странице. Конечно, в таком случае предпочтительным могло бы быть сканирование таблицы — в этом случае сервер обращался бы к каждой странице данных только один раз. Однако этому часто мешают… попытки оптимизации запросов, когда разработчик явно указывает, какой индекс или тип соединения должен быть использован. Обратный случай — вместо использования индекса было выбрано сканирование таблицы. Как правило, это связано с тем, что статистика устарела и требуется её обновление. Однако и в этом случае причиной неудачно выбранного плана вполне могут оказаться подсказки оптимизатору запросов.
query_text — текст самого запроса
database_name — имя базы данных, в находится объект, содержащий запрос.
NULL для системных процедур
object_name — имя объекта (процедуры или функции), содержащего запрос.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
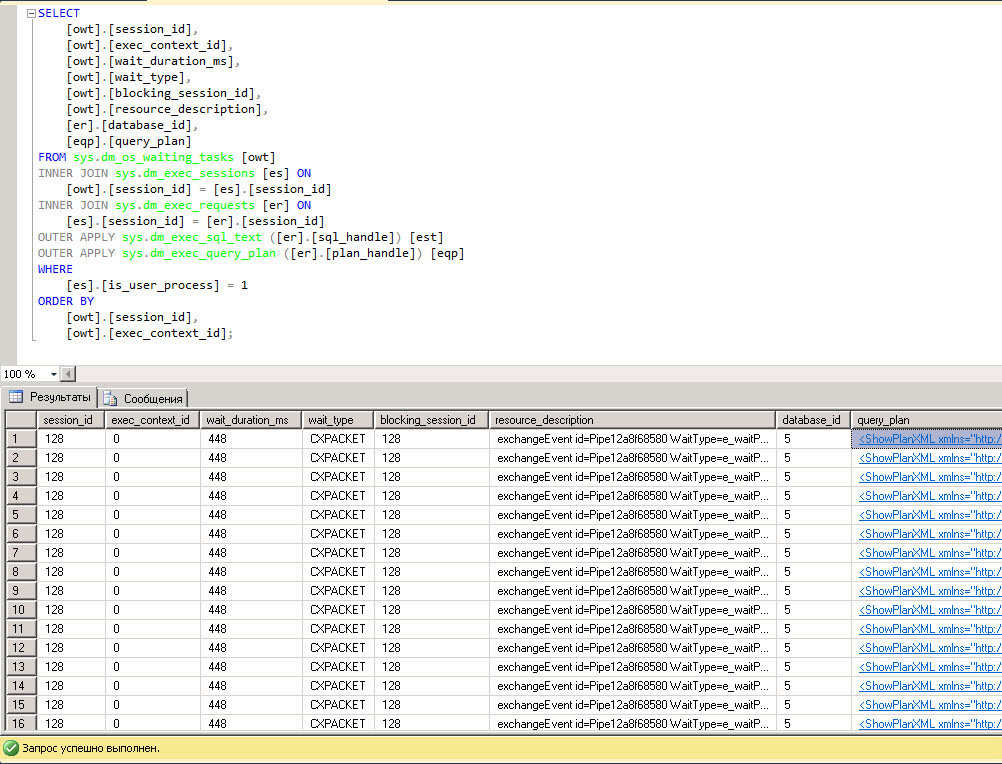
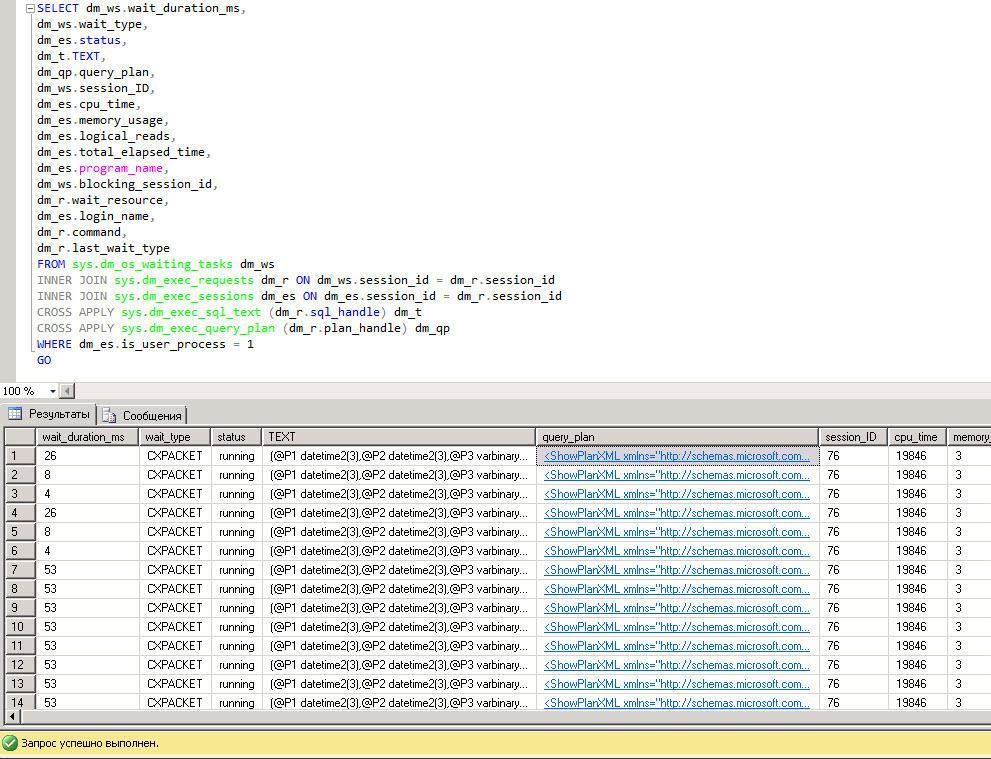
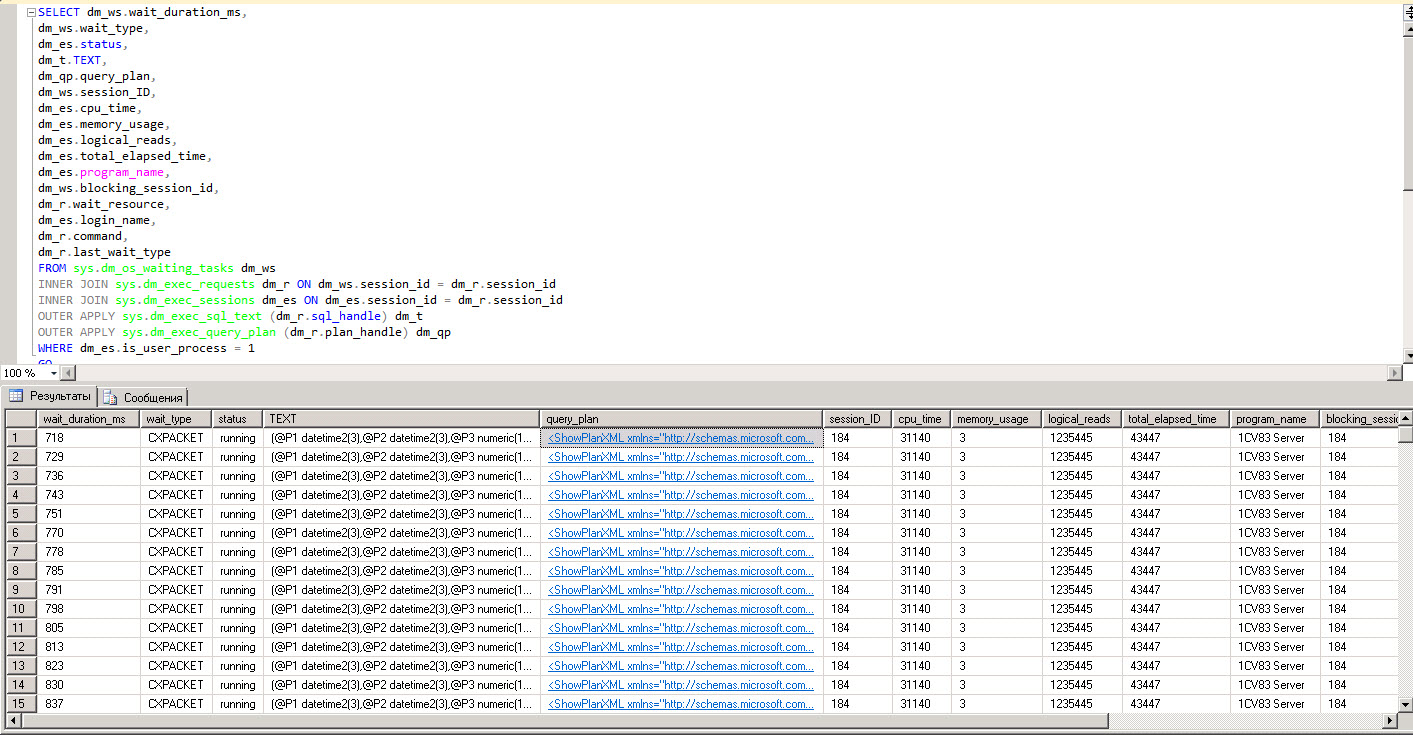
with s as ( select creation_time, last_execution_time, execution_count, total_worker_time/1000 as CPU, convert(money, (total_worker_time))/(execution_count*1000)as [AvgCPUTime], qs.total_elapsed_time/1000 as TotDuration, convert(money, (qs.total_elapsed_time))/(execution_count*1000)as [AvgDur], total_logical_reads as [Reads], total_logical_writes as [Writes], total_logical_reads+total_logical_writes as [AggIO], convert(money, (total_logical_reads+total_logical_writes)/(execution_count + 0.0))as [AvgIO], [sql_handle], plan_handle, statement_start_offset, statement_end_offset from sys.dm_exec_query_stats as qs with(readuncommitted) where convert(money, (qs.total_elapsed_time))/(execution_count*1000)>=100 --выполнялся запрос не менее 100 мс ) select s.creation_time, s.last_execution_time, s.execution_count, s.CPU, s.[AvgCPUTime], s.TotDuration, s.[AvgDur], s.[Reads], s.[Writes], s.[AggIO], s.[AvgIO], --st.text as query_text, case when sql_handle IS NULL then ' ' else(substring(st.text,(s.statement_start_offset+2)/2,( case when s.statement_end_offset =-1 then len(convert(nvarchar(MAX),st.text))*2 else s.statement_end_offset end - s.statement_start_offset)/2 )) end as query_text, db_name(st.dbid) as database_name, object_schema_name(st.objectid, st.dbid)+'.'+object_name(st.objectid, st.dbid) as [object_name], sp.[query_plan], s.[sql_handle], s.plan_handle from s cross apply sys.dm_exec_sql_text(s.[sql_handle]) as st cross apply sys.dm_exec_query_plan(s.[plan_handle]) as sp |




Здравствуйте. А можно эту страничку сделать читаемой? )
Добрый день
Исправляю