Postgres — бесплатная SQL база данных. Начиная с версии 8.3 платформа 1С поддерживает PostgreSQL версий 9.4 и 9.6. Для этого фирмой 1С был выпущен набор патчей для PostgreSQL 9.4.2 и 9.6.1 Эти версии СУБД имеют множество улучшений, прежде всего связанных с надежностью. В данной статье рассмотрен пример offnline установки SQL сервера Postgres для работы с кластером 1С Предприятие. В качестве серверного дистрибутива выбран CentOS 7
Дистрибутивы
В качестве дистрибутива использованы пакеты с официального сайта 1С версии 9.6.7-1.1C. На данный момент не тестировались сборки PostgresPro, которые, как уверяют разработчики, являются улучшенными версиями официальных пакетов компании 1С. Получить их можно по следующей ссылке. В ближайшее время я все же попытаюсь сравнить эти версии и оценить стабильность работы. Так же есть еще один канал — Etersoft
Хочу отметить, что инсталляцию необходимо проводить на ветке 9.6, так как она официально заявлена рабочей. На 10 версии Postgres тестирование проводилось и результат отличный!!!
Установка
Сейчас интернет есть даже у холодильника, но я столкнулся с ситуацией, когда на площадке Интернет был только на рабочем месте. Не буду вдаваться в подробности почему и как — по факту. Дело не благородное, но вариантов нет! Если у вас есть выход в Интернет, то данную часть можно пропустить. И так, для установки понадобятся следующие пакеты, которых нет в дистрибутиве Centos 7 minimal — bzip2, libicu, libxslt и tcl. Как это сделать, описано в статье Использование YUM для закачки пакетов
Если все дистрибутивы (качестве дистрибутива использованы пакеты с официального сайта 1С версии 9.6.7-1.1C) скачаны и заброшены на сервер, можно приступить к установке
Распаковка архивов
|
1 2 3 4 |
tar -xvf postgresql_9.6.7_1.1C_x86_64_rpm.tar.bz2 tar -xvf postgresql_9.6.7_1.1C_x86_64_addon_rpm.tar.bz2 |
Установка PostgresSQL
|
1 2 3 4 |
cd postgresql-9.6.7-1.1C_x86_64_rpm yum localinstall -y *.rpm |
Установка дополнений
|
1 2 3 4 |
cd postgresql-9.6.7-1.1C_x86_64_addon_rpm/ yum localinstall -y *.rpm |
Инициализация базы данных и запуск Postgres
Переключаемся на пользователя postgres
|
1 2 3 |
su - postgres |
Запуск инициализации системной базы с указанием кодировки и рабочего каталога
|
1 2 3 4 5 6 7 8 9 |
/usr/pgsql-9.6/bin/initdb --locale=ru_RU.UTF-8 -D /var/lib/pgsql/9.6/data/ ... Success. You can now start the database server using: /usr/pgsql-9.6/bin/pg_ctl -D /var/lib/pgsql/9.6/data/ -l logfile start |
Запуск сервера Postgres
|
1 2 3 4 5 |
/usr/pgsql-9.6/bin/pg_ctl -D /var/lib/pgsql/9.6/data/ -l logfile start server starting |
Настройка файла pg_hda.conf
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# TYPE DATABASE USER ADDRESS METHOD # "local" is for Unix domain socket connections only local all all trust # IPv4 local connections: #host all all 127.0.0.1/32 ident host all all 0.0.0.0/0 password # IPv6 local connections: host all all ::1/128 ident # Allow replication connections from localhost, by a user with the # replication privilege. #local replication postgres trust #host replication postgres 127.0.0.1/32 trust #host replication postgres ::1/128 trust |
Подключение в базе
|
1 2 3 4 5 |
sudo -u postgres /usr/pgsql-9.6/bin/psql psql (9.6.7) Type "help" for help. |
Устанавливаем пароль пользователя postgres
|
1 2 3 4 5 |
postgres=# ALTER USER postgres WITH PASSWORD 'PGPASSWORD'; ALTER ROLE postgres=# \q |
Проверка локализации и работоспособности
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
psql -l List of databases Name | Owner | Encoding | Collate | Ctype | Access privileges -----------+----------+----------+-------------+-------------+----------------------- postgres | postgres | UTF8 | ru_RU.UTF-8 | ru_RU.UTF-8 | template0 | postgres | UTF8 | ru_RU.UTF-8 | ru_RU.UTF-8 | =c/postgres + | | | | | postgres=CTc/postgres template1 | postgres | UTF8 | ru_RU.UTF-8 | ru_RU.UTF-8 | =c/postgres + | | | | | postgres=CTc/postgres (3 rows) |
Перезагрузка сервера
|
1 2 3 |
shutdown -r now |
Настройка подключения
После перезагрузки запустим вручную и добавим в автозагрузку
Отроем порт Postgres на фаерволе для подключения или отключим совсем
|
1 2 3 4 |
firewall-cmd --permanent --zone=public --add-port=5432/tcp firewall-cmd --reload |
Отключение фаервола
Отключим SELinux
|
1 2 3 4 |
vi /etc/hosts 192.168.1.252 1c 1c.domain |
|
1 2 3 |
192.168.1.20 pgsql |
Перезагрузка
|
1 2 3 |
shutdown -r now |
Настройка базы данных в кластере 1С Предприятие
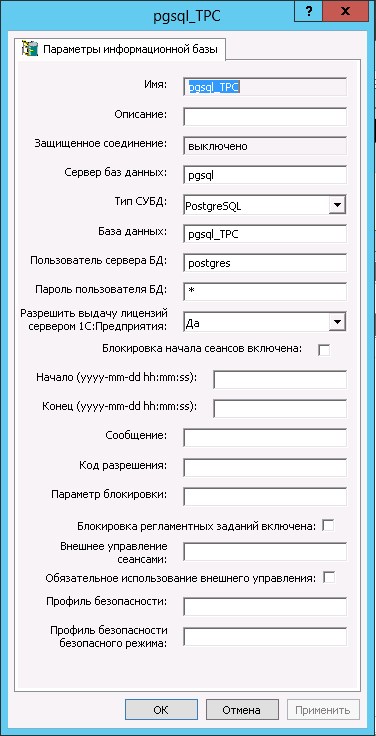
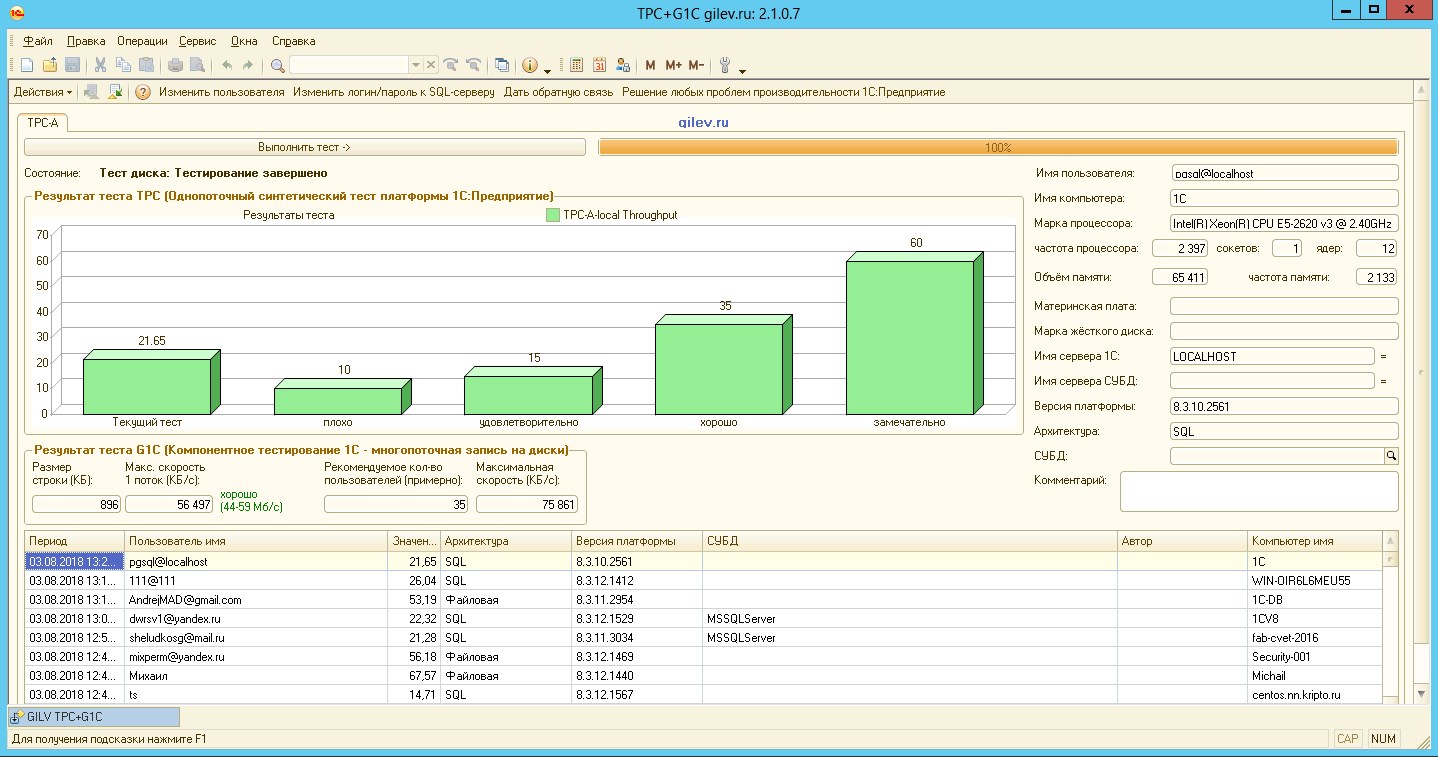
Оптимизация настроек Postgresql для сервера 1С Предприятие
Некоторые параметры разъяснены в этой статье. Сохраним резервную копию файла настроек
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 |
#---------------------------------------------------------------------- listen_addresses = '*' # what IP address(es) to listen on; dynamic_shared_memory_type = posix # the default is the first option log_destination = 'stderr' # Valid values are combinations of log_rotation_age = 1d # Automatic rotation of logfiles will datestyle = 'iso, dmy' timezone = 'W-SU' lc_messages = 'ru_RU.UTF-8' # locale for system error message lc_monetary = 'ru_RU.UTF-8' # locale for monetary formatting lc_numeric = 'ru_RU.UTF-8' # locale for number formatting lc_time = 'ru_RU.UTF-8' # locale for time formatting default_text_search_config = 'pg_catalog.russian' #---------------------------------------------------------------------- effective_cache_size = '12288MB' work_mem = '32MB' shared_buffers = '12288MB' maintenance_work_mem = '512MB' temp_buffers = '32MB' #temp_tablespaces = 'user_temp' max_files_per_process = '24576' autovacuum_max_workers = '4' autovacuum_analyze_scale_factor = '0.01' autovacuum_vacuum_scale_factor = '0.02' random_page_cost = '1.5' log_statement = 'none' #---------------------------------------------------------------------- log_filename = 'postgresql-%Y-%m-%d.log' log_rotation_size = '0' log_timezone = 'W-SU' log_truncate_on_rotation = 'on' logging_collector = 'on' shared_preload_libraries = 'online_analyze, plantuner, auto_explain' online_analyze.enable = off online_analyze.verbose = off online_analyze.table_type = 'temporary' online_analyze.scale_factor = 0.3 online_analyze.min_interval = 10000 online_analyze.threshold = 500 online_analyze.local_tracking = on cpu_operator_cost = 0.0005 plantuner.fix_empty_table = on autovacuum_naptime = '20' #autovacuum_analyze_threshold = 20 bgwriter_delay = '10' # ms bgwriter_lru_maxpages = '800' bgwriter_lru_multiplier = '8' # storage specific effective_io_concurrency = '2' random_page_cost = '2' checkpoint_completion_target = 0.9 #checkpoint_segments = '128' max_connections = '1000' synchronous_commit = 'off' commit_delay = '1000' # 1C specific escape_string_warning = 'off' standard_conforming_strings = 'off' max_locks_per_transaction = '256' #work_mem = 65536 # pgbadger log_directory = 'pg_log' #log_directory = '/var/log/pgsql' #log_filename = 'postgresql.log' log_min_duration_statement = 0s log_autovacuum_min_duration = 0 log_line_prefix = '%t [%p]: [%l-1] user=%u,db=%d,app=%a,client=%h ' log_checkpoints = on log_connections = on log_disconnections = on log_lock_waits = on log_temp_files = 0 # backup max_wal_senders = 4 wal_level = hot_standby wal_keep_segments = 1024 |
Конфигурация рассчитана на 32Gb оперативной памяти.
Описание параметров с сайта infostat
При настройке сервера для тестирования я полагался на следующие расчеты:
Всего 4Гб ОЗУ. Потребители — ОС Windows, сервер 1С, PostgreSQL и дисковый кэш системы. Я исходил из того что для СУБД можно выделить до 2.5Гб ОЗУ
Значения могут указываться с суффиксами kB, MB, GB (значения в килобайта, мегабайтах или гигабайтах). После изменения значений требуется перезапустить службу PostgreSQL.
shared_buffers — Общий буфер сервера
Размер кэша чтения и записи PostgreSQL, общего для всех подключений. Если данные отсутствуют в кэше, производится чтение с диска (возможно, будут кэшированы ОС)
Если объём буфера недостаточен для хранения часто используемых рабочих данных, то они будут постоянно писаться и читаться из кэша ОС или с диска, что крайне отрицательно скажется на производительности.
Но это не вся память, требуемая для работы, не следует указывать слишком большое значение, иначе не останется памяти как для собственно выполнения запросов клиентов (а чем их больше тем выше потребление памяти), так и для ОС и прочих приложений, например, процесса сервера 1С. Так же сервер полагается и на кэш ОС и старается не держать в своём буфере то что скорее всего закэшировано системой.
Начальные рекомендации:
Средний объем данных, доступно 256-512Мб — значения 16-32Мб
Большой объем данных, доступно 1-4Гб — значения 64-256Мб или выше.
В тесте использовалось
shared_buffers = 512MB
work_mem — память для сортировки, агрегации данных и т.д.
Выделяется на каждый запрос, возможно по нескольку раз для сложных запросов. Если памяти недостаточно — PostgreSQL будет использовать временные файлы. Если значение слишком большое — может возникнуть перерасход оперативной памяти и ОС начнет использовать файл подкачки с соответствующим падением быстродействия.
Есть рекомендация при расчетах взять объем доступной памяти за вычетом shared_buffers, и поделить на количество одновременно исполняемых запросов. В случае сложных запросов делитель стоит увеличить, т.е. уменьшить результат. Для рассматриваемого случая из расчета 5 активных пользователей (2.5Гб-0.5Гб (shared_buffers))/5=400Мб. В случае если СУБД сочтет запросы достаточно сложными, или появятся дополнительные пользователи, потребуется значение уменьшить.
Для простых запросов достаточно небольших значений — до пары мегабайт, но для сложных запросов (а это типовой сценарий для 1С) потребуется больше. Рекомендация — для памяти 1-4Гб можно использовать значения 32-128Мб. В тесте использовал
work_mem = 128MB
maintenance_work_mem — память для команд сбора мусора, статистики, создания индексов.
Рекомендуется устанавливать значение 50-75% от размера самой большой таблицы или индекса, но чтобы памяти хватило для работы системы и приложений. Рекомендуется устанавливать значения больше чем work_mem. В тесте использовал
maintenance_work_mem = 192MB
temp_buffers — буфер под временные объекты, в основном для временных таблиц.
Можно установить порядка 16 МБ. В тесте использовал
temp_buffers = 32MB
effective_cache_size — примерный объем дискового кэша файловой системы.
Оптимизатор использует это значение при построении плана запроса, для оценки вероятности нахождения данных в кэше (с быстрым случайным доступом) или на медленном диске. В Windows текущий объем памяти, выделенной под кэш, можно посмотреть в диспетчере задач.
Autovacuum — «сборка мусора»
PostgreSQL как типичный представитель «версионных» СУБД (в противоположность блокирующим) самостоятельно не блокирует при изменении данных таблицы и записи от читающих транзакций (в случае 1С этим занимается сам сервер 1С). Вместо этого создаётся копия изменяемой записи, которая становится видна последующим транзакциям, действующие же продолжают видеть данные, актуальные на начало своей транзакции. Как следствие, в таблицах накапливаются устаревшие данные — предыдущие версии измененных записей. Для того чтобы СУБД могла высвободившееся место использовать, необходимо произвести «сборку мусора» — определить какие из записей больше не используются. Это можно сделать явно SQL-командой VACUUM, либо дождаться когда таблицу обработает автоматический сборщик мусора — AUTOVACUUM.
Так же до определенной версии сборка мусора была связана со сбором статистики (планировщик использует данные о количестве записей в таблицах и распределении значений индексированных полей для построения оптимального плана запроса). С одной стороны, сбор мусора делать необходимо, чтобы таблицы не разрастались и эффективно использовали дисковое пространство. С другой внезапно начавшаяся уборка мусора дает дополнительную нагрузку на диск и таблицы, что приводит к увеличению времени выполнения запросов. Аналогичный эффект создает автоматический сбор статистики (явно его можно запустить командой ANALYZE или совместно со сборкой мусора VACUUM ANALYZE). И хотя от версии к версии PostgreSQL совершенствует эти механизмы, чтобы минимизировать негативное влияние на производительность (например, в ранних версиях сборка мусора полностью блокировала доступ к таблице, с версии 9.0 работа VACUUM ускорена), тут есть что настроить.
Полностью отключить autovacuum можно параметром:
autovacuum = off
Так же для работы Autovacuum требуется параметр track_counts = on, в противном случае он работать не будет.
По умолчанию оба параметра включены. На самом деле autovacuum полностью отключить нельзя — даже при autovacuum = off иногда (после большого количества транзакций) autovacuum будет запускаться.
Отключать autovacuum крайне не рекомендуется, иначе имеет смысл самостоятельно запланировать регулярное выполнение команды VACUUM ANALYZE.
Замечание: VACUUM обычно не уменьшает размер файла таблицы, только помечает свободные, доступные для повторного использования области. Если же требуется физически высвободить лишнее место и максимально уменьшить занимаемое пространство на диске, потребуется команда VACUUM FULL. Этот вариант блокирует доступ к таблице на время работы, и обычно не требуется его использовать. Подробнее об использовании команды VACUUM можно прочитать в документации (на английском).
Если Autovacuum полностью не отключать, настроить его влияние на выполнение запросов можно следующими параметрами:
autovacuum_max_workers — максимальное количество параллельно запущенных процессов уборки.
autovacuum_naptime — минимальный интервал, реже которого autovacuum не будет запускаться. По умолчанию 1 минута. Можно увеличить, тогда при частых изменениях данных анализ будет выполняться реже.
autovacuum_vacuum_threshold, autovacuum_analyze_threshold — количество измененных или удаленных записей в таблице, необходимых для запуска процесса сборки мусора VACUUM или сбора статистики ANALYZE. По умолчанию по 50.
autovacuum_vacuum_scale_factor, autovacuum_analyze_scale_factor — коэфициент от размера таблицы в записях, добавляемый к autovacuum_vacuum_threshold и autovacuum_analyze_threshold соответственно. Значения по умолчанию 0.2 (т.е. 20% от количества записей) и 0.1 (10%) соответственно.
Рассмотрим пример с таблицей на 10000 записей. Тогда при настройках по умолчанию после 50+10000*0.1=1050 измененных или удаленных записей будет запущен сбор статистики ANALYZE, а после 2050 изменений — сборка мусора VACUUM.
Если увеличить threshold и scale_factor, обслуживающие процессы будут выполняться реже, но небольшие таблицы могут существенно разрастаться. Если БД состоит преимущественно из небольших таблиц, общее увеличение занимаемого дискового пространства может быть существенным, таким образом увеличивать эти значения можно, но с умом.
Таким образом может иметь смысл увеличить интервал autovacuum_naptime, и несколько увеличить threshold и scale_factor. В нагруженных базах может быть альтернативой существенно поднять scale_factor (значение 1 позволит «разбухать» таблицам вдвое) и поставить в планировщик ежесуточное выполнение VACUUM ANALYZE в период минимальной загруженности БД.
default_statistics_target — назначает объем статистики, собираемый командой ANALYZE. Значение по умолчанию 100. Большие значения увеличивают время выполнения команды ANALYZE, но позволяют планировщику строить более эффективные планы выполнения запросов. Встречаются рекомендации по увеличению до 300.
Можно управлять производительностью AUTOVACUUM, делая его более длительным но менее нагружающим систему.
vacuum_cost_page_hit — размер «штрафа» за обработку блока, находящегося в shared_buffers. Связан с необходимостью блокировать доступ к буферу. Значение по умолчанию 1
vacuum_cost_page_miss — размер «штрафа» за обработку блока на диске. Связан с блокировкой буфера, поиском данных в буфере, чтении данных с диска. Значение по умолчанию 10
vacuum_cost_page_dirty — размер «штрафа» за модификацию блока. Связан с необходимостью сбросить модифицированные данные на диск. Значение по умолчанию 20
vacuum_cost_limit — максимальный размер «штрафов», после которых процесс сборки может быть «заморожен» на время vacuum_cost_delay. По умолчанию 200
vacuum_cost_delay — время «заморозки» процесса сборки мусора по достижению vacuum_cost_limit. Значение по умолчанию 0ms
autovacuum_vacuum_cost_delay — время «заморозки» процесса сборки мусора для autovacuum. По умолчанию 20ms. Если установить -1, будет использоваться значение vacuum_cost_delay
autovacuum_vacuum_cost_limit — максимальный размер «штрафа» для autovacuum. Значение по умолчанию -1 — используется значение vacuum_cost_limit
По сообщениям использование vacuum_cost_page_hit = 6, vacuum_cost_limit = 100, autovacuum_vacuum_cost_delay = 200ms уменьшает влияние AUTOVACUUM до 80%, но увеличивает время его выполнения втрое.
Настройка записи на диск. При завершении транзакции PostgreSQL начала пишет данные в специальный журнал транзакций WAL (Write-ahead log), а затем уже в базу после того, как данные журнала гарантированно записаны на диск. По умолчанию используется механизм fsync, когда PostgreSQL принудительно сбрасывает данные (журнала) из дискового кэша ОС на диск, и только после успешной записи (журнала) клиенту сообщается об успешном завершении транзакции. Использование журнала транзакций позволяет завершить транзакцию или восстановить базу если во время записи данных произойдет сбой.
В нагруженных системах с большими объемами записи может иметь смысл вынести журнал транзакций на отдельный физический диск (но не на другой раздел этого же диска!). Для этого нужно остановить СУБД, перенести каталог pg_xlog в другое место, а на старом месте создать символическую ссылку, например, утилитой junction. Так же ссылки умеет создавать Far Manager (Alt-F6). При этом надо убедиться что новое место имеет права доступа для пользователя, от которого запускается PostgreSQL (обычно postgres).
При большом количестве операций изменения данных может потребоваться увеличить значение checkpoint_segments, регулирующее объем данных, который может ожидать переноса из журнала в саму базу. По умолчанию используется значение 3. При этом следует учитывать что под журнал выделяется место, расчитываемое по формуле (checkpoint_segments * 2 + 1) * 16 МБ, что при значении 32 уже потребует более 1Гб места на диске.
PostgreSQL после каждого завершения пишущей транзакции сбрасывает данные из файлового кэша ОС на диск. С одной стороны, это гарантирует что данные на диске всегда в актуальном состоянии, с другой при большом количестве транзакций падает производительность. Полностью отключить fsync можно, указав
fsync = off
full_page_writes = off
Делать это можно только в случае если вы на 100% доверяете оборудованию и ИБП (источнику бесперебойного питания). Иначе в случае аварийного завершения системы есть риск получить разрушенную БД. И в любом варианте не помешает так же RAID-контроллер с батарейкой для питания памяти недозаписанных данных.
Определенной альтернативой может быть использование параметра
synchronous_commit = off
В этом случае после успешного ответа на завершение транзакции до безопасной записи на диск может пройти некоторое время. В случае внезапного отключения база не разрушится, но могут быть потеряны данные последних транзакций.
Если не отключать fsync совсем, можно указать метод синхронизации в параметре. Статья с диска ИТС ссылается на утилиту pg_test_fsync, но в моей сборке PostgreSQL её не оказалось. По утверждению 1С, в их случае в Windows оптимально себя показал метод open_datasync (судя по всему, именно этот метод и используется по умолчанию).
В случае если используется множество мелких пишущих транзакций (в случае 1С этом может быть массовое обновление справочника вне транзакции), может помочь сочетание параметров commit_delay (время задержки завершения транзакции в микросекундах, по умолчанию 0) и commit_siblings (по умолчанию 5). При включении опций завершение транзакции может быть отложено на время commit_delay, если в данный момент исполняется не менее commit_siblings транзакций. В этом случае результат всех завершившихся транзакций будет записан совместно для оптимизации записи на диск.
Прочие параметры, влияющие на производительность
wal_buffers — объем памяти в shared_buffers для ведения транзакционных логов. Рекомендация — при 1-4Гб доступной памяти использовать значения 256КБ-1МБ. Документация утверждает что использование значения «-1» автоматически подбирает значение в зависимости от значения shared_buffers.
random_page_cost — «стоимость» случайного чтения, используется при поиске данных по индексам. По умолчанию 4.0. За единицу берется время последовательного доступа к данным. Для быстрых дисковых массивов, особенно SSD, имеет смысл понижать значение, в этом случае PostgreSQL будет более активно использовать индексы.
В книге по ссылке есть некоторые другие параметры, которые можно настраивать. Так же настоятельно рекомендуется ознакомиться с документацией на PostgreSQL по назначению конкретных параметров.
Параметры из раздела QUERY TUNING, особенно касающиеся запрета планировщику использовать конкретные методы поиска, рекомендуется изменять только в том случае если есть полное понимание что делаете. Очень легко оптимизировать один вид запросов и обрушить производительность всех остальных. Эффективность изменения большинства параметров в этом разделе зависит от данных в БД, запросов к этим данным (т.е. от используемой версии 1С в т.ч.) и версии СУБД.
Индивидуальные настройки можно выполнить на этом сайте
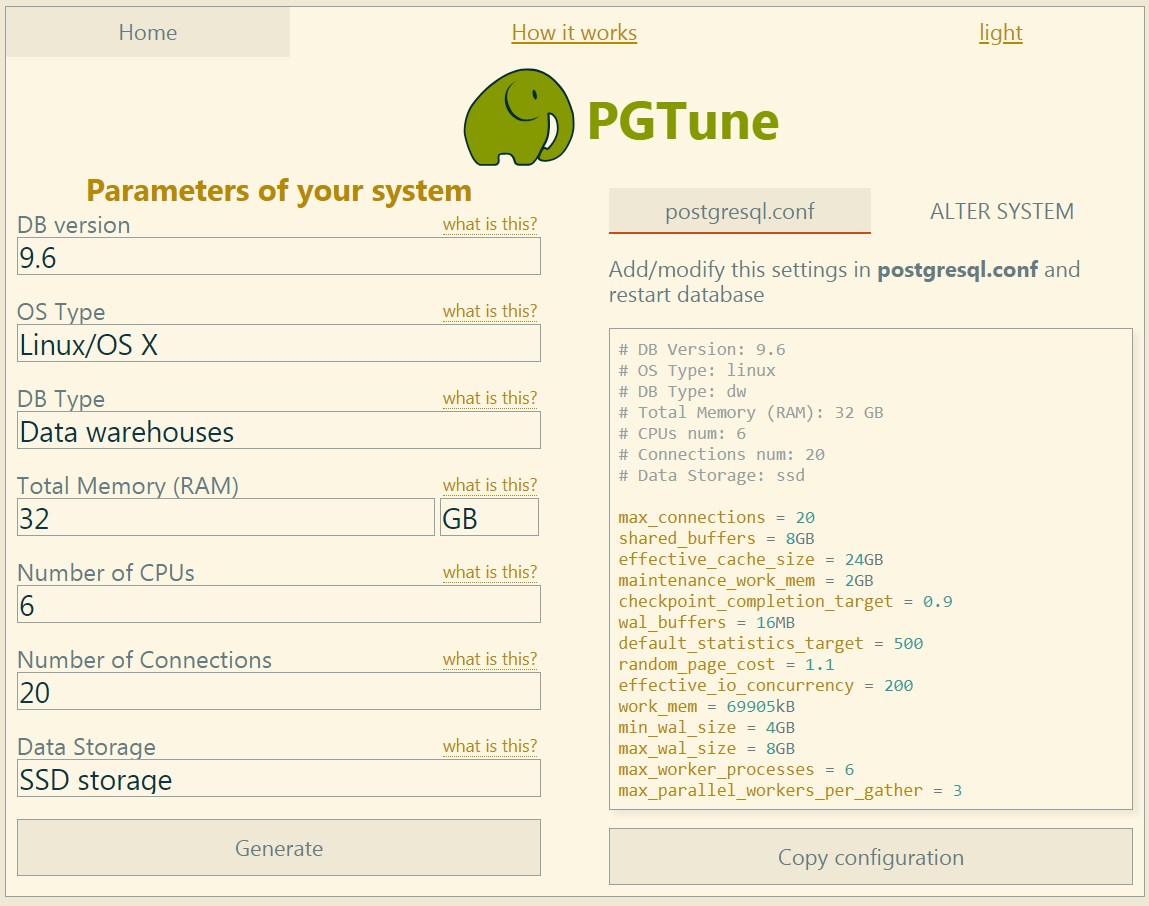
Архивация
Простой скрипт архивации
|
1 2 3 |
pg_dump -U postgres WMS | gzip > /backup/WMS-$(date +%Y-%m-%d).gz |
где -U postgres имя пользователя базы данных
WMS имя базы данных для архивации
gzip выполняет сжатие резервной копии
/backup/WMS-$(date +%Y-%m-%d).gz каталог для архивации и имя файла архива, с указанием времени выполнения архивации. В качестве каталога может выступать удаленное хранилище NFS или iSCSI, что позволить сохранить данные, в случае выхода из строя сервера на котором запущена виртуальная машина.
Если ни чего не работает
Описание с сайта Гилева Хорошая статья, о том, если что не работает. Возможно что то удастся выцепить из комментариев.
Немного мутно, но как то по делу видео Еще один более толковый ролик И статья на infostart
Установка сервера PostgreSQL 10 для 1С Предприятие
Если совсем ни чего не работает!!!
Пишите, постараюсь помочь.



Спасибо. Единственная рабочая инструкция. Очень благодарен.
Спасибо за отклик! Хорошо, что получилось настроить по данной статье, потому что мог пропустить что-то. Ну и просто приятно, когда твой труд оценивают )
Все настроил — работает. вот только проблема в том что отчеты очень долго формируются. в разы дольше чем в файловом варианте. А в чем проблема так и не могу найти
Доброго времени суток.
Что может быть:
1. Тюнинг операционной системы — это кеш под статистику в виде RAM раздела
2. Отключение некоторых демонов ОС — tuned, например, может снижать производительность, переводя систему в режим пониженного энергопотребления, задержки при работе с дисковой подсистемой (можно задать параметры монтирования EXT4)
3. Параметры PGSQL — выбор параметров используемой ОП, потоков, использование AVTOUVACUUM
Что можно сделать:
1. Тестирование производительности тестами Гилева, подобрав необходимые параметры
2. Использование новой версии PGSQL — https://www.kost.su/%d1%83%d1%81%d1%82%d0%b0%d0%bd%d0%be%d0%b2%d0%ba%d0%b0-%d1%81%d0%b5%d1%80%d0%b2%d0%b5%d1%80%d0%b0-postgresql-10-%d0%b4%d0%bb%d1%8f-1%d1%81-%d0%bf%d1%80%d0%b5%d0%b4%d0%bf%d1%80%d0%b8%d1%8f%d1%82%d0%b8/
3. Оценить производительность после внесения изменений в настройки